
Google Crawling là một thuật ngữ quen thuộc với những ai làm SEO hay quan tâm đến cách thức hoạt động của Google. Nhưng bạn có biết Google Crawling là gì? Cách hoạt động và các lỗi thường gặp trong quá trình Crawling không? Hãy cùng tìm hiểu qua bài viết này nhé!
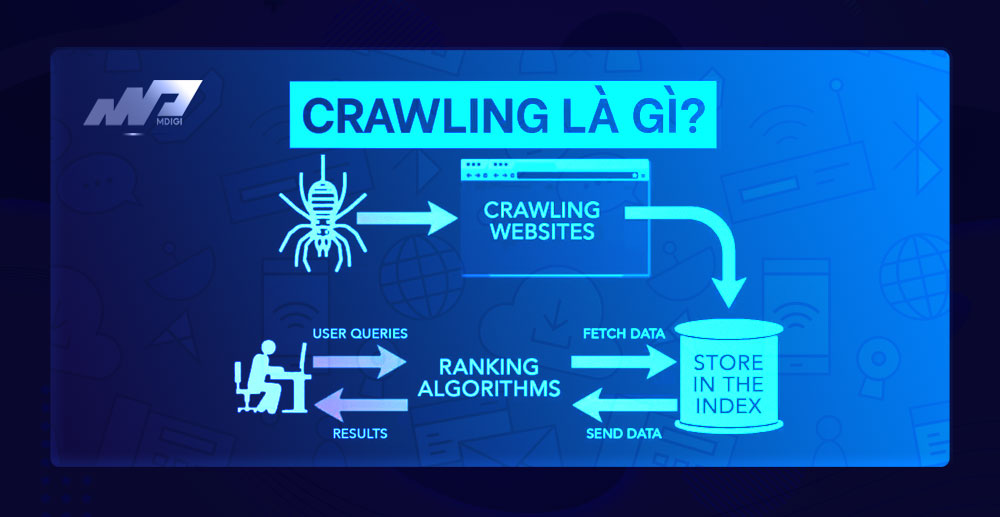
Google Crawling là gì?
Google Crawling (hay còn gọi là thu thập thông tin) là quá trình khám phá trong đó Googlebot (trình thu thập dữ liệu của Google) sẽ tìm kiếm và cập nhật nội dung mới trên Internet. Nội dung có thể là trang web, video, hình ảnh, PDF,… và được phát hiện bởi các liên kết.
Đây được xem là một quá trình quan trọng trong SEO vì nó giúp Google lập chỉ mục và xếp hạng các trang web trên kết quả tìm kiếm. Nếu một trang web không được Googlebot thu thập thông tin, nó sẽ không xuất hiện trên Google Search.
Cách hoạt động của Googlebot khi Crawling các trang web
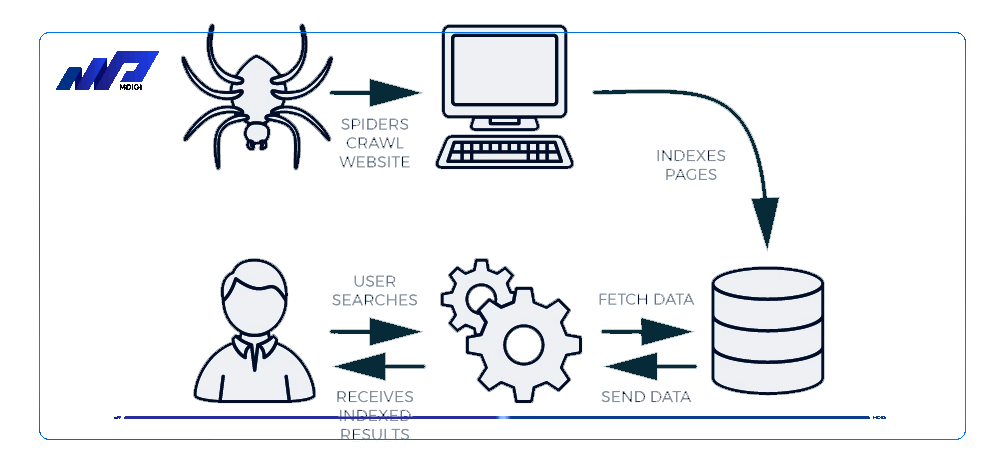
Googlebot là một chương trình máy tính tự động được Google sử dụng để thu thập thông tin các trang web. Googlebot hoạt động theo các bước sau:
- Bắt đầu từ một số trang web đã biết hoặc được cung cấp bởi Sitemap.xml.
- Từ những trang web này, Googlebot sẽ tìm kiếm các liên kết khác dẫn đến các trang web mới.
- Googlebot sẽ tải về nội dung của các trang web mới và lưu vào Caffeine – cơ sở dữ liệu lớn về URL của Google
- Googlebot sẽ kiểm tra file Robots.txt để xem có những trang web nào không cho phép thu thập thông tin và tuân thủ theo yêu cầu.
- Googlebot sẽ lặp lại quá trình này cho đến khi thu thập được hết nội dung mong muốn hoặc hết ngân sách thu thập thông tin (Crawling budget).
Các yếu tố ảnh hưởng đến tốc độ và hiệu quả của Crawling
Crawling là một quá trình tốn nhiều tài nguyên của Google và của website. Do đó, để tối ưu hóa quá trình Crawling, bạn cần chú ý đến các yếu tố sau:
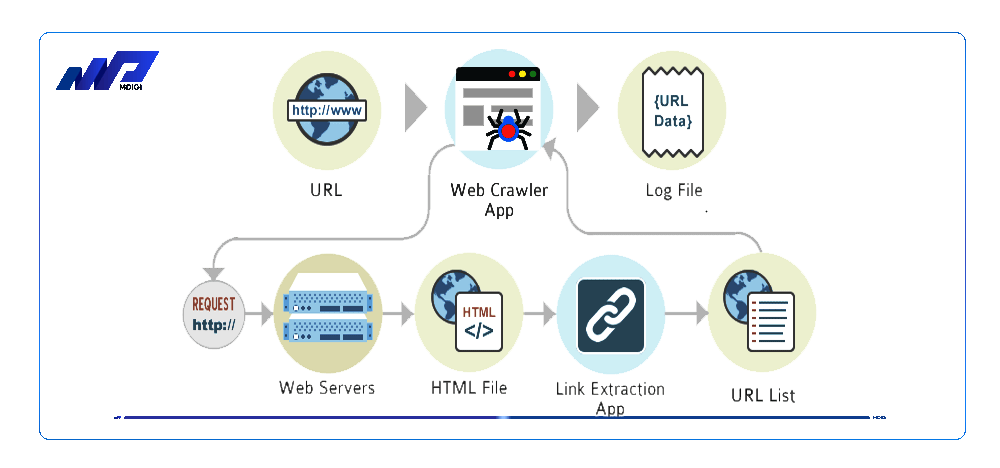
Crawling budget: Đây là số lượng URL mà Googlebot có thể và muốn thu thập thông tin trong một khoảng thời gian nhất định. Crawling budget bao gồm hai khái niệm: Crawling limit (giới hạn thu thập thông tin) và Crawling demand (nhu cầu thu thập thông tin). Bạn có thể kiểm tra Crawling budget của website trong Google Search Console.
Robots.txt: Đây là một file văn bản đặt ở thư mục gốc của website, có chức năng chỉ định cho Googlebot biết những trang web nào được phép hoặc không được phép thu thập thông tin. Bạn có thể sử dụng Robots.txt để chặn Googlebot truy cập vào những trang web không cần thiết, như trang quản trị, trang đăng nhập, trang tạm thời,… để tiết kiệm Crawling budget.
Sitemap.xml: Đây là một file văn bản định dạng XML, chứa danh sách các URL của website và một số thông tin bổ sung, như tần suất cập nhật, mức độ ưu tiên, ngày sửa đổi cuối,… Bạn có thể sử dụng Sitemap.xml để thông báo cho Googlebot về những trang web mới hoặc cập nhật của website, giúp Googlebot dễ dàng tìm thấy và thu thập thông tin.
Tốc độ tải trang: Đây là thời gian mà một trang web cần để hiển thị hoàn toàn nội dung cho người dùng. Tốc độ tải trang không chỉ ảnh hưởng đến trải nghiệm người dùng mà còn ảnh hưởng đến quá trình Crawling. Nếu tốc độ tải trang quá chậm, Googlebot sẽ mất nhiều thời gian hơn để thu thập thông tin, làm giảm Crawling budget và số lượng URL được thu thập. Do đó, bạn nên tối ưu hóa tốc độ tải trang bằng cách nén ảnh, giảm số lượng yêu cầu HTTP, sử dụng bộ nhớ đệm, minify CSS và JavaScript,…
Các lỗi thường gặp trong quá trình Crawling
Trong quá trình Crawling, có thể xảy ra một số lỗi khiến Googlebot không thể thu thập thông tin được các trang web mong muốn. Dưới đây là một số lỗi thường gặp và cách khắc phục:
Lỗi điều hướng website: Đây là lỗi xảy ra khi website của bạn có những liên kết bị hỏng, không tồn tại hoặc bị chuyển hướng quá nhiều lần. Lỗi này khiến Googlebot không thể tiếp cận được nội dung của các trang web đó, làm giảm khả năng xếp hạng và ảnh hưởng đến SEO. Để khắc phục lỗi này, bạn nên kiểm tra và sửa chữa các liên kết bị hỏng, sử dụng mã trạng thái HTTP 301 để chuyển hướng vĩnh viễn các URL cũ sang URL mới, và tránh sử dụng quá nhiều chuyển hướng liên tiếp.
Lỗi máy khách 4xx: Đây là lỗi xảy ra khi máy khách (client) gửi yêu cầu không hợp lệ đến máy chủ (server). Lỗi này khiến Googlebot không thể thu thập thông tin được các trang web đó, làm giảm khả năng xếp hạng và ảnh hưởng đến SEO. Lỗi máy khách 4xx có nhiều loại, trong đó phổ biến nhất là lỗi 404 (Not Found), tức là URL không tồn tại hoặc đã bị xóa. Để khắc phục lỗi này, bạn nên kiểm tra và sửa chữa các URL bị lỗi, sử dụng mã trạng thái HTTP 301 để chuyển hướng vĩnh viễn các URL cũ sang URL mới, hoặc tạo một trang 404 tùy chỉnh để hướng dẫn người dùng đến các trang web liên quan .
Lỗi máy chủ 5xx: Đây là lỗi xảy ra khi máy chủ (server) gặp sự cố khi xử lý yêu cầu của máy khách (client). Lỗi này khiến Googlebot không thể thu thập thông tin được các trang web đó, làm giảm khả năng xếp hạng và ảnh hưởng đến SEO. Lỗi máy chủ 5xx có nhiều loại, trong đó phổ biến nhất là lỗi 500 (Internal Server Error), tức là máy chủ gặp lỗi nội bộ không rõ nguyên nhân. Để khắc phục lỗi này, bạn nên kiểm tra và sửa chữa các vấn đề về mã nguồn, cơ sở dữ liệu, tệp .htaccess, hoặc liên hệ với nhà cung cấp dịch vụ hosting để được hỗ trợ.
Câu hỏi thường gặp
Bạn có thể sử dụng công cụ URL Inspection trong Google Search Console để kiểm tra trạng thái Crawling và Indexing của một URL cụ thể trên trang web của bạn. Bạn chỉ cần nhập URL vào ô tìm kiếm và nhấn Enter, bạn sẽ thấy kết quả như sau:
Nếu URL đã được Google Crawling và Indexing, bạn sẽ thấy thông báo “URL is on Google” và các thông tin chi tiết về ngày Crawling cuối cùng, nguồn Crawling, trạng thái Indexing, sơ đồ trang web,…
Nếu URL chưa được Google Crawling và Indexing, bạn sẽ thấy thông báo “URL is not on Google” và các lý do có thể gây ra điều này, chẳng hạn như URL bị chặn bởi Robots.txt, URL bị loại bỏ khỏi Google Search bởi yêu cầu của bạn hoặc của chủ sở hữu trước đó, URL không tồn tại hoặc bị lỗi,…
Ngoài ra, bạn cũng có thể yêu cầu Google Crawling lại URL của bạn bằng cách nhấn vào nút “Request indexing” nếu bạn muốn cập nhật nội dung mới hoặc sửa chữa các lỗi.
Googlebot có thể thu thập thông tin được hầu hết các loại tệp và định dạng phổ biến trên Internet, như HTML, CSS, JavaScript, PDF, DOCX, XLSX, PPTX, RTF, SVG, PNG, JPG,… Tuy nhiên, có một số loại tệp mà Googlebot không thể thu thập thông tin được hoặc chỉ thu thập thông tin một phần, chẳng hạn như Flash, AJAX, Silverlight,… Do đó, bạn nên tránh sử dụng các loại tệp này để chứa nội dung quan trọng cho trang web của bạn.
Không phải. Googlebot chỉ thu thập thông tin các trang web mà nó biết hoặc tìm được thông qua các liên kết từ các trang web khác. Do đó, nếu trang web của bạn mới được tạo hoặc không có liên kết từ các trang web uy tín khác, có khả năng Googlebot sẽ không biết đến và thu thập thông tin nó. Để giúp Googlebot tìm được trang web của bạn, bạn nên đăng ký và xác minh trang web của bạn với Google Search Console , gửi sơ đồ trang web cho Google , và xây dựng các liên kết chất lượng từ các trang web liên quan đến trang web của bạn.
Không phải. Googlebot là tên chung cho một số bot khác nhau của Google , mỗi bot có một mục đích và chức năng riêng. Ví dụ:
– Googlebot Desktop: Bot này thu thập thông tin các trang web dành cho máy tính để bàn và laptop.
– Googlebot Mobile: Bot này thu thập thông tin các trang web dành cho điện thoại thông minh và máy tính bảng.
– Googlebot Image: Bot này thu thập thông tin các hình ảnh trên các trang web.
– Googlebot Video: Bot này thu thập thông tin các video trên các trang web.
– Googlebot News: Bot này thu thập thông tin các trang web tin tức.
Bạn có thể xác định Googlebot bằng cách kiểm tra User-Agent trong tệp nhật ký máy chủ của bạn hoặc sử dụng công cụ Verify Googlebot để kiểm tra một địa chỉ IP cụ thể có phải là Googlebot hay không.
Tổng quan
Google Crawling là quá trình thu thập thông tin trên Internet của Googlebot để lập chỉ mục và xếp hạng các trang web trên kết quả tìm kiếm. Để tối ưu hóa quá trình Crawling, bạn cần chú ý đến các yếu tố như Crawling budget, Robots.txt, Sitemap.xml, tốc độ tải trang,… và khắc phục các lỗi thường gặp trong quá trình Crawling như lỗi điều hướng website, lỗi máy khách 4xx, lỗi máy chủ 5xx,… Hy vọng bài viết này đã giúp bạn hiểu rõ hơn về Google Crawling là gì và cách hoạt động của nó. Nếu bạn có bất kỳ câu hỏi hay góp ý nào, hãy để lại bình luận bên dưới nhé!
